论文阅读 Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features into LSTMs for Chinese Grammatical Error Diagnosis Task
这篇论文是阿里在IJCNLP-2017 中文错误诊断任务上的工作介绍。
1.介绍
中文语法形式灵活多变,给初学者容易犯一些错误,因此对于初学者来说,一套自动的中文语法错误诊断系统是有极大帮助的。
2.中文语法错误诊断
这项任务始于2014年,主要有四种类型的错误:冗余词错误(R)、词语选择错误(S)、丢失词错误(M)、词语顺序错误(R),错误类型如下:

3 相关工作
此处略
4.方法论述
4.1 模型介绍
类似于哈工大的论文https://xianpengcui.com/2020/02/12/chinese-grammatical-error-diagnosis-with-long-short-term-memory-networks/,这里也是采用的LSTM-CRF模型,模型架构如下图所示:
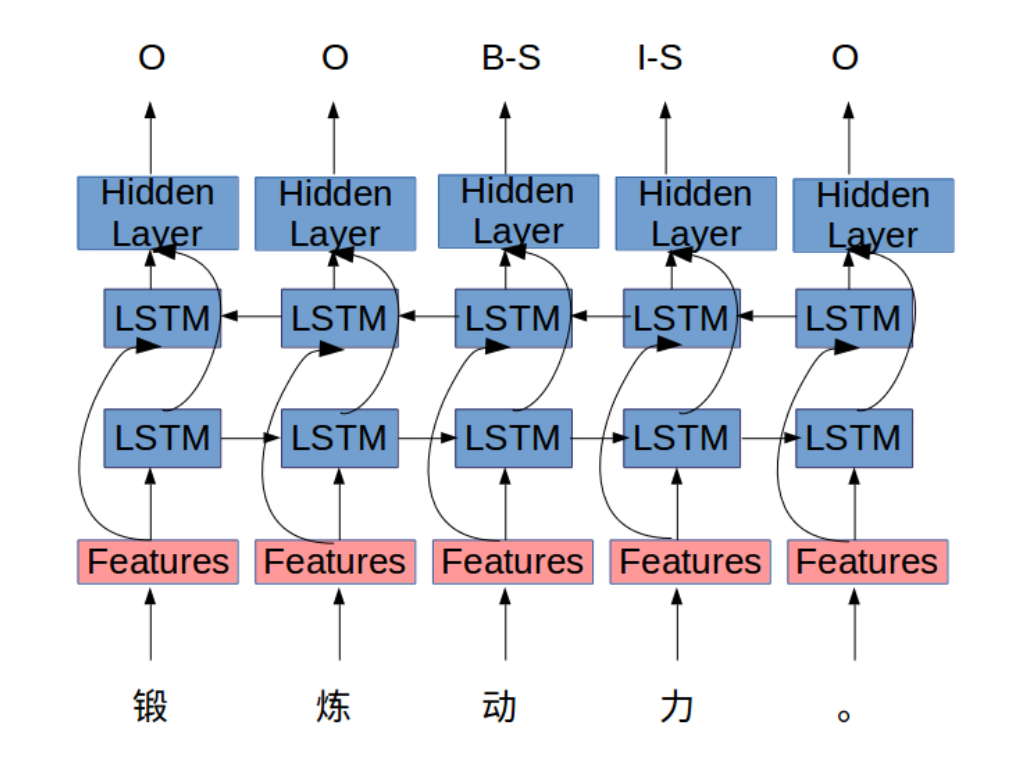
4.2 特征工程
因为训练数据的缺乏,这个任务比较依赖于先验知识,比如词性等。下面是作者采用的一些特征信息:
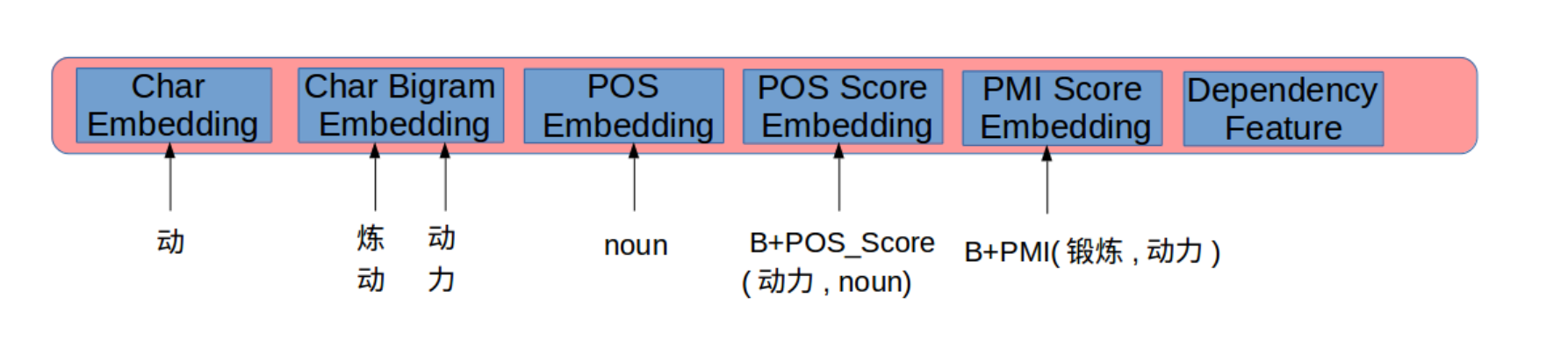
字符:序列标注是以字符级为粒度,这里直接将字符embedding作为输入特征,embedding为随机初始化。
二元字符:二元信息是一个主要特征,可以让模型学到相邻字符之间的聚合程度。二元信息的获取与HIT组相同。
词性:字符级别,如B-pos,I-pos
词性得分:通过分析训练语料发现,很多错误词的识别出的词性并不是这个词语多数情况下表现出来的词性。通过Gigawords数据集来计算出词性的离散特征作为输入特征。
临近词语的搭配:使用Gigawords数据集数据集来计算临近词语PMI得分。错误词语搭配的PMI得分会比较低。
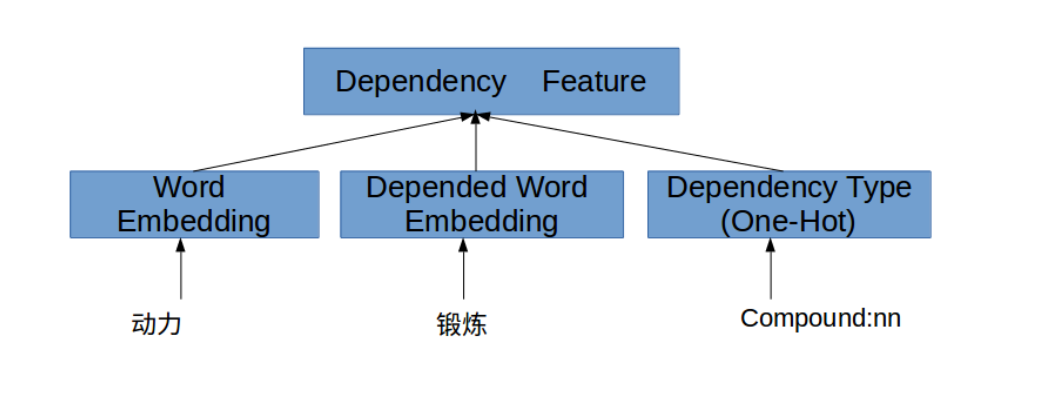
依赖词语搭配:
搭配不仅存在于临近词语,依赖词语直接也存在,这里通过依赖解析获取词语之间的依赖关系。
4.3 模型组合
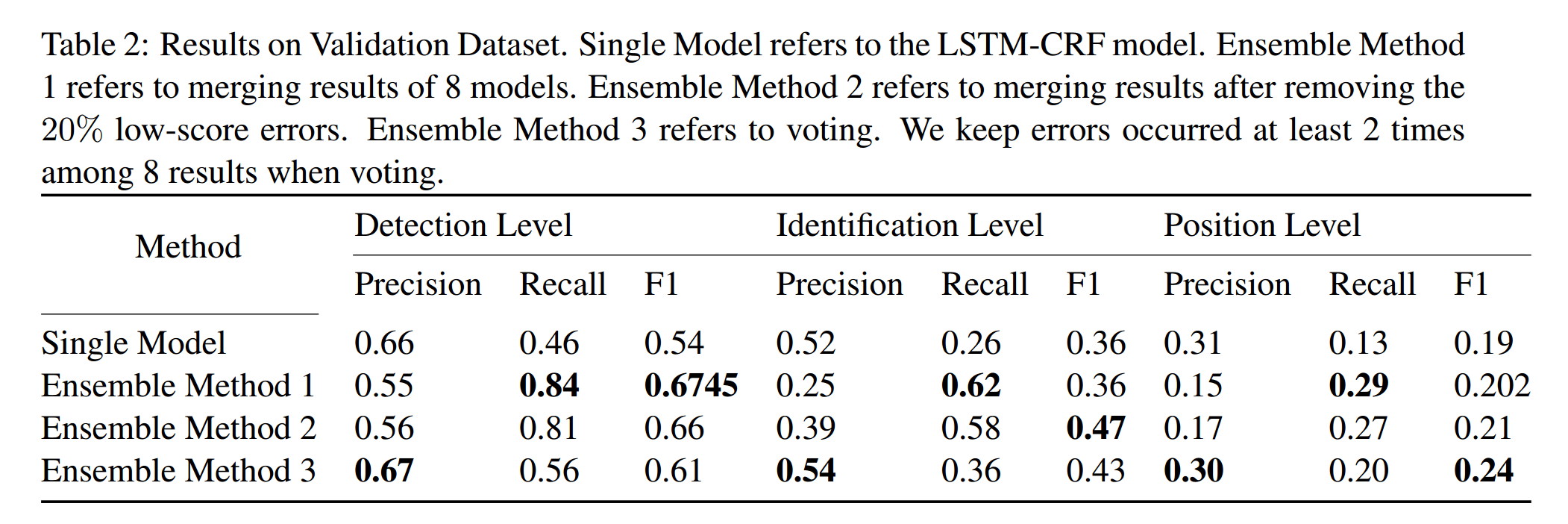
因为采用随机初始化的策略,及时采用相同的预训练参数,模型在每词训练的预测结果也差别很大。因为作者设计了3个不同的组合模型。第一个模型是简单的合并结果,通过使用发现召回率有提高,但是同时准确率下降的也挺厉害。为了平衡准确率和召回率,提出了第二个模型,用LSTM-CRF生成的得分来对每个模型生成的错误进行排序,删除20%的错误,然后合并结果,这个模型可以提高一定程度的准确率,但是跟单一模型没法比。第三个模型是投票的方式。
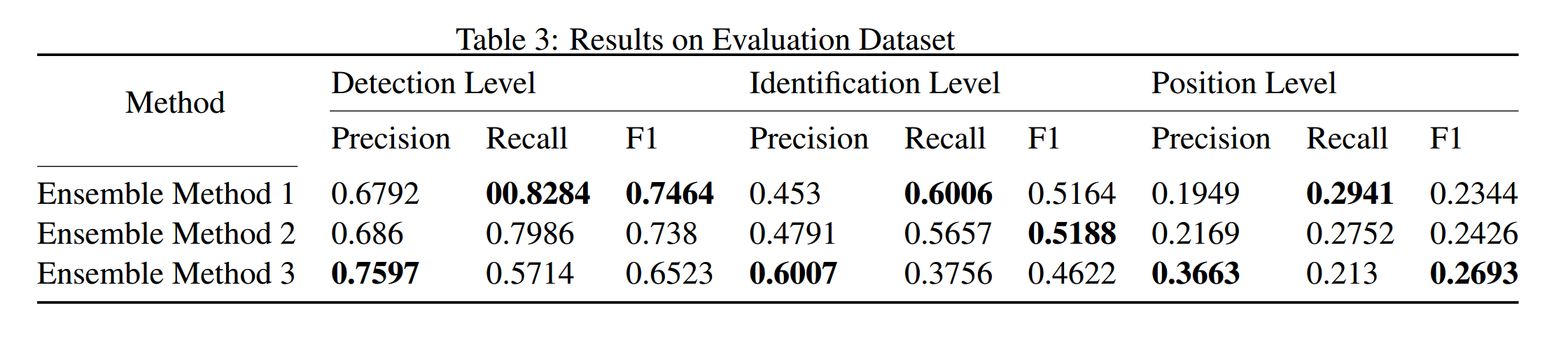
在实际试验中,采用了4组参数,每组参数训练2个模型,这样得到了8个模型。3组模型在任务的3个级别都取得了F1的最好值。
5.试验
5.1 数据划分和试验设定
收集了2015、2016、2017年的数据,2017年中20%的数据作为验证集,剩下的作为训练。使用Gigawords数据集预训练了二元embedding和字符embedding,并且训练中保持固定不变。其他参数随机初始化。
5.2 实验结果
5.2.1 验证集上的结果
5.2.2 测试集上的结果

LeetCode 88. Merge Sorted Array

LeetCode 33. Search in Rotated Sorted Array
