Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data 论文介绍
这篇论文是猿辅导在语法纠错方面的新论文,借鉴了文本摘要方面的copy机制,并结合多任务学习,取得了不错的效果,下面来时介绍。
摘要
作者针对语法纠错提出了copy机制,即将未变化的词从原始句子拷贝到目标句子。针对语法纠错任务缺乏标注语料的问题,采用大量的未标注语料降噪自编码来预训练copy机制模型。同时还增加了token级别和句子级别的联合训练任务。
1. Introduction
语法错误纠正(GEC)任务是检测并纠正文本中的语法错误。机器翻译系统在GEC中取得了不错的效果,但是GEC不同于翻译的地方在于GEC只是改动句子中的几个词语,下表统计了不同语料集中,原始句子和目标句子相同的比例。可以看到80%以上的词语是可以直接从原始句子中拷贝过去的。
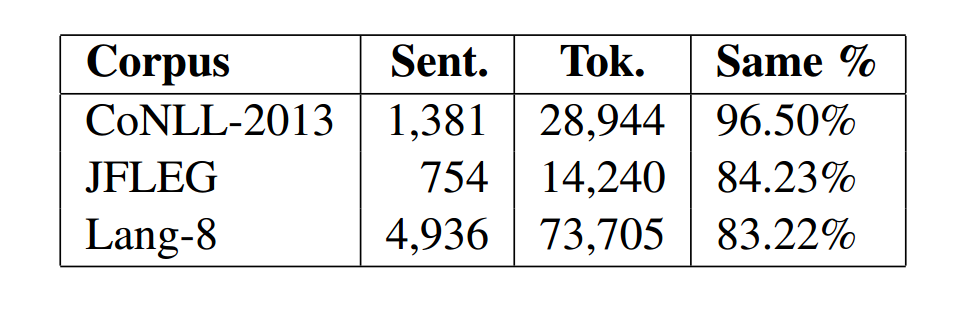
针对GEC任务中未变化词语占比较高的比例,作者在网络结构中引入拷贝机制,通过从原始句子中拷贝未变化词语和未登录词。针对标记语料缺乏的问题,作者通过降噪自编码对未标记语料进行预训练。同时为GEC增加了两个联合训练任务,一个是toker级别的标记任务,另一个是句子级别的拷贝任务。
2. 方法介绍
2.1 基本架构
作者将Transformer作为baseline,关于Transformer这里就不详细介绍了。
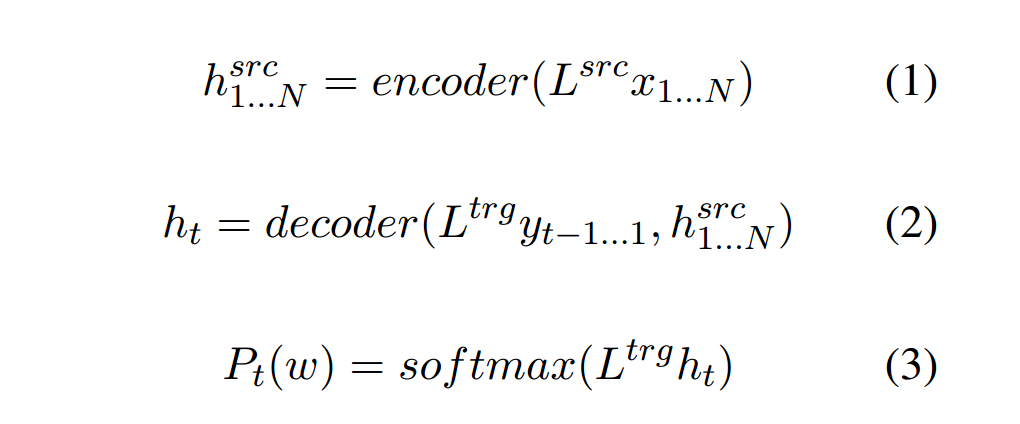
2.2 Copy机制
Copy机制在文本摘要任务中取得了有效的成果,这里第一次将其应用到GEC任务中。如下图的架构图,拷贝增强网络既可以从固定的词典中生成词语,也可以从原始输入端拷贝词语。
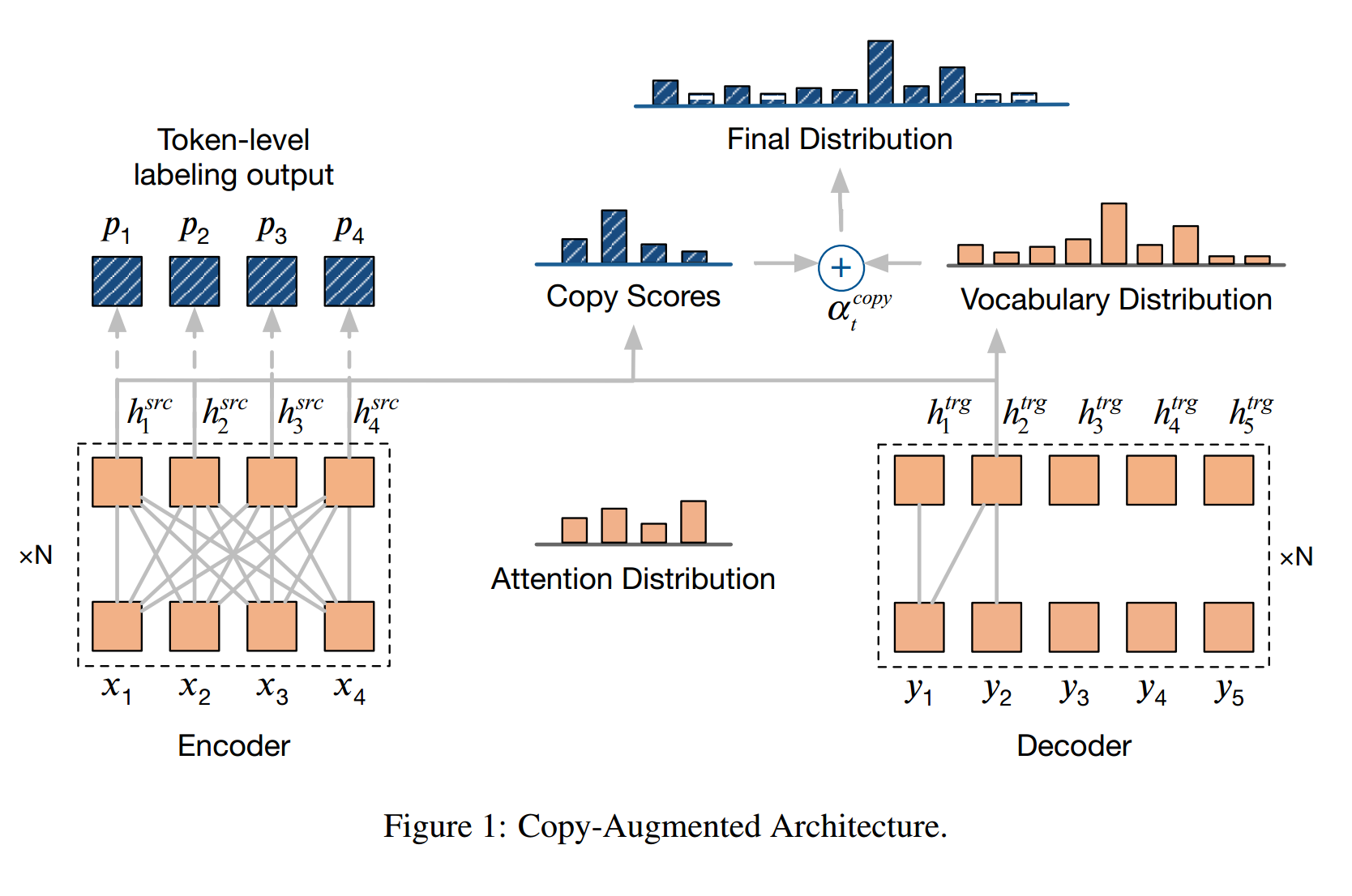
下面的公式中最终概率分别\(P_t\)混合了生成概率分布\(P_t^{gen}\)和拷贝概率分布\(P_t^{copy}\)。二者之间的平衡是通过平衡因子\(α_t^{copy}\)来控制的。copy分值是通过attention分布来计算的,是关于当前隐层和输入层之间的attention分布。
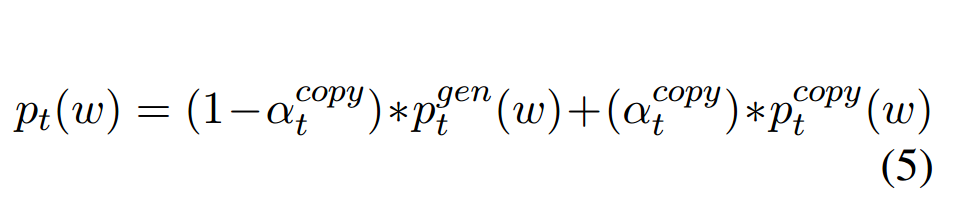
copy attention是通过如下公式计算的:
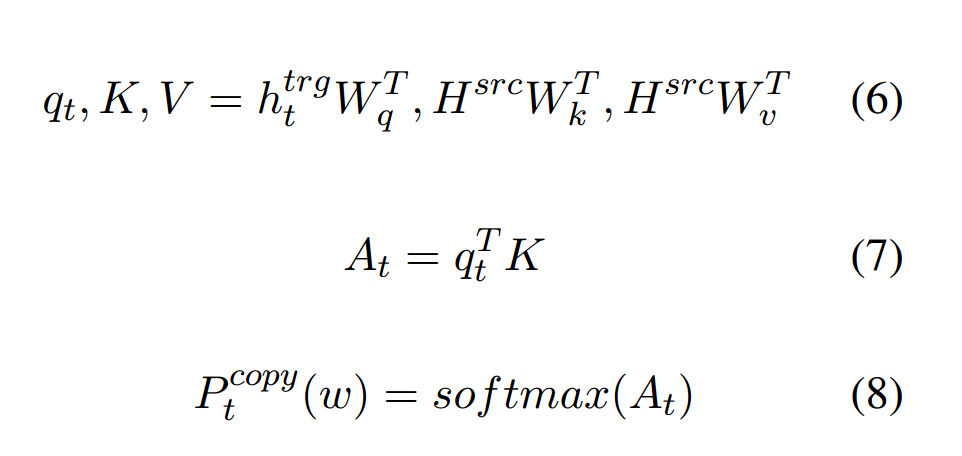
3. 预训练
在很多缺乏大量训练语料的任务中,预训练是一种很好的方法。作者采用了降噪自编码的方式来预训练大量的未标记数据。
3.1 降噪自编码
降噪自编码常用于模型初始化时从输入中提取和选择特征,BERT使用双向transformer模型,在多数NLP任务中的表现都超过了现有系统。BERT在处理的过程中选取了15%的词语,在这15%的词语中:80%的词语使用MASK代替,10%采用随机词语,剩下的10%保持原有词语。
作者借鉴了BERT和降噪自编码思想,作者对于未标记的语料对做了如下处理:
- 10%的概率删除一个词语。
- 10%的概率增加一个词语。
- 10%的概率随机替换一个词语。
- 按照一个正太分布的偏差打散词语。
3.2 预训练decoder
在NLP任务中,预训练部分模型也同样能够提升效果。作者初始化拷贝机制的decoer通过预训练参数形式,其他参数进行随机初始化。
4.多任务学习
为提升GEC的性能,作者增加了两个任务。
4.1 token级别的标注任务
作者为元素词语增加了token级别的标注任务,具体说来就是标识原始句子中的每个词语是否正确。
公式如下:
对于原始句子中的每个词语\(x_i\),对应于目标句子中的一个词语\(y_j\),如果\(x_i=y_j\),则将其标注为正确,否则则为错误。预测的时候是通过将encoder最终状态\(h_i^{src}\)送入softmax。
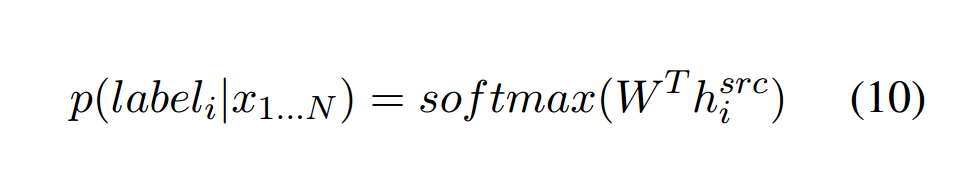
4.2 句子级别的拷贝机制
这个任务的主要目的是当句子看似整体正确时,做尽可能多的拷贝。训练过程中将相等数量的正确句子和修改的句子对输入到模型中,当输入的是正确句子时,移除decoder层的atttntion处理。
5.评测
作者使用的训练集和评测集如下:
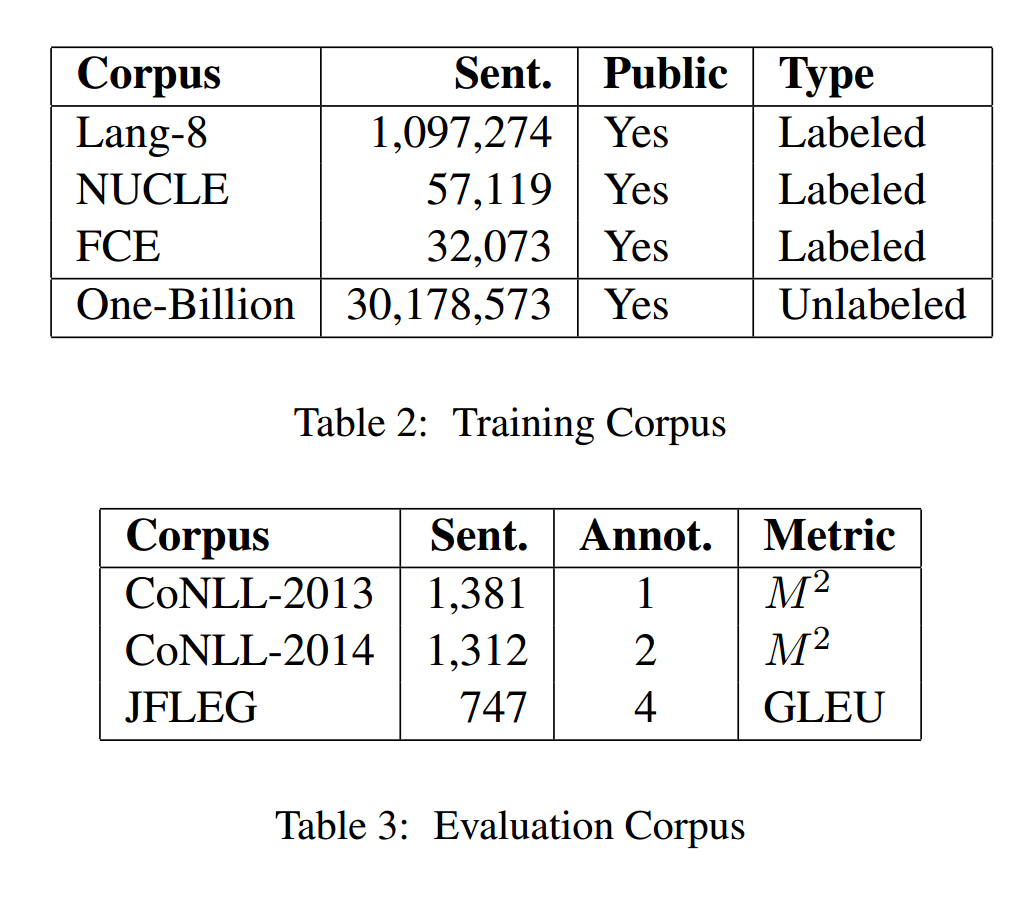
作者训练了一个基于统计的拼写纠错模型,来处理训练语料。
5.2 模型和训练设置
在这里作者使用的是Facebook FAIR实现的Transformer工具包fairseq。对于transformer模型,embedding和隐层的大小是512维,encoder和decoder是6层8个head,dropout=0.2。
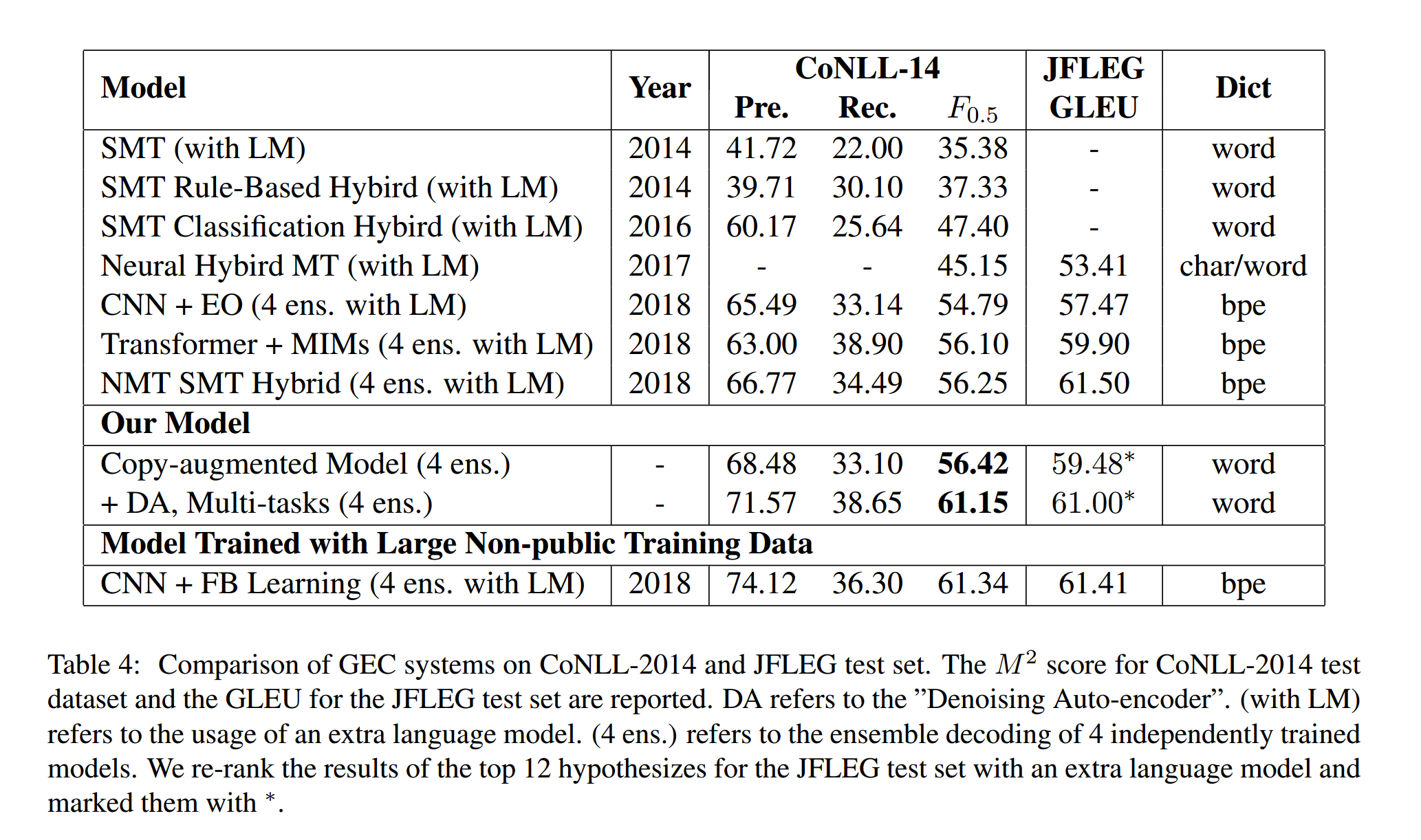
5.3实验结果
5.4 Ablation Study
5.4.1 拷贝机制探究
对比了GEC任务中Transformer架构中有无copy机制的结果,对比结果如下图。增加拷贝机制后\(F_{0.5}\)得分从48.07提升到了54.67。另外拷贝机制不单单对于UNK词语的处理有提升,除此之外对纠错整体效果也有提升,\(F_{0.5}\)有1.62的提升。
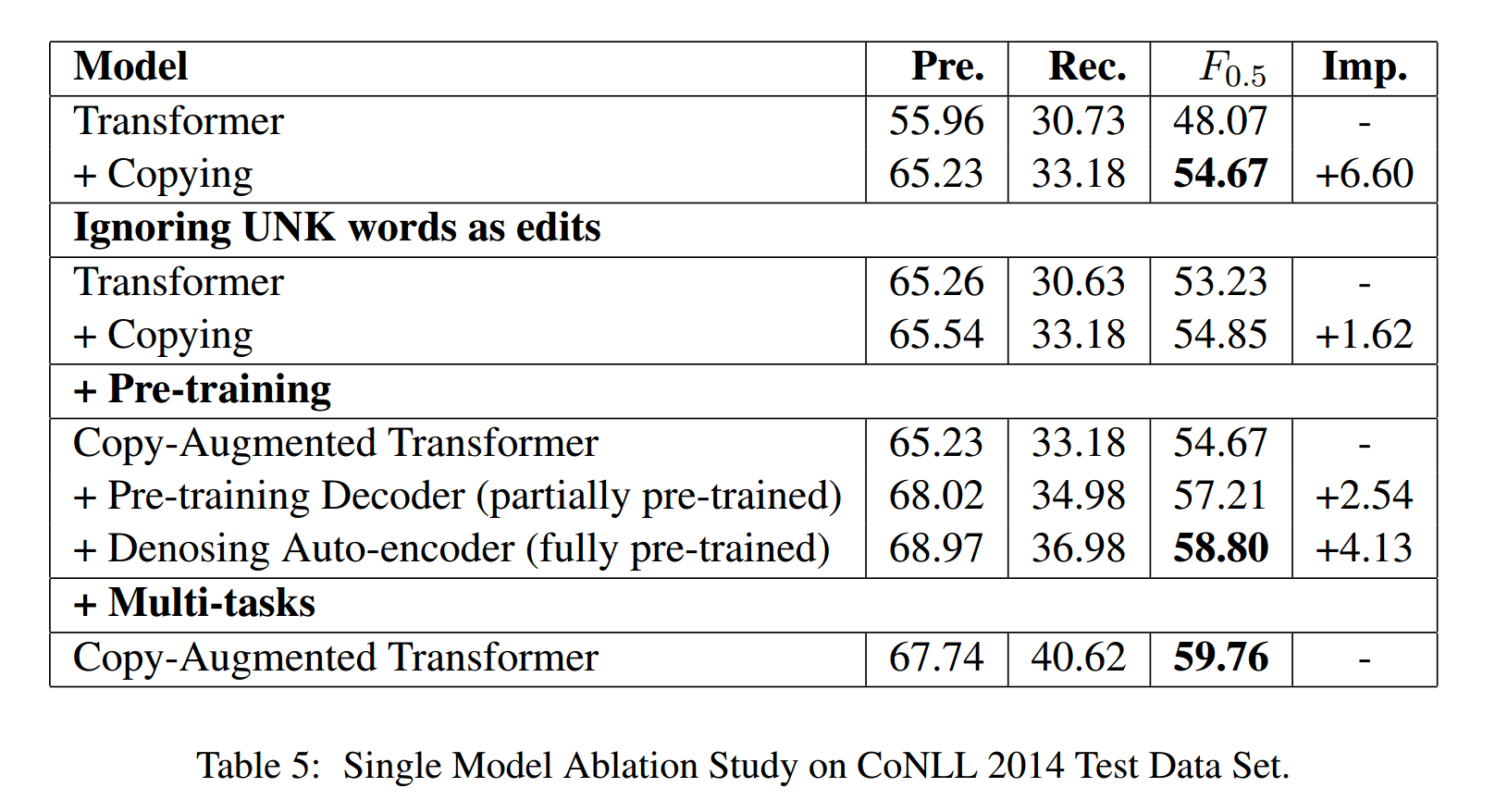
5.4.2 预训练任务探究
从上图中可以看出预训练机制对于\(F_{0.5}\)得分有2.54的提升,而应用降噪自编码后,有4.13的提升
5.5 Attention 可视化

上图中拷贝机制更关注正确序列中的下一个词,而生成机制更关注其他词语。也就意味着生成机制更关注长依赖和全局信息。
论文地址:

