噪声信道模型用于纠错 An Improved Error Model for Noisy Channel Spelling Correction
1.噪声信道模型
噪声信道模型是一个非常重要的模型,它在很多领域都有非常重要的应用。它是在上世纪80年代在语音识别领域引起人们的重视的。
噪声信道模型的形式很简单,如图所示:

噪声信道试图通过有噪声的输出信号恢复输入信号。它用下面的公式定义:
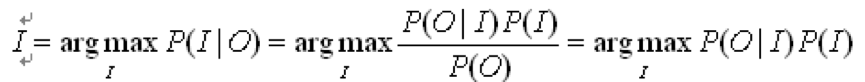
对于某一输入信号,此信号通过会产生噪声的转换信道得到输出信号,现在假设我们已知道输出信号,求解它的输入信号,那么就会用到此模型。
已知道输出为O,求解它的最大可能输入I,即在O下条件概率最大的那个I,通过贝叶斯公式转换就可以得到:
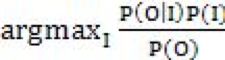
对于某一个特定的输出,显然P(O)是不变的,所以可以不用管P(O),于是原式可以再次化简为argmaxP(o|I)P(I). 我们一般把P(I)叫做语言模型,P(O|I)叫做信道模型或者称为error model。
2. 论文模型介绍
在这篇文章之前,信道模型已经应用很广泛,只不过很少用在纠错任务中。这篇文章提出了一个改进的信道模型,通过通用的字符到字符之间的编辑操作,并且每个操作赋予概率值,纠错准确率有了很大提升。
在之前的纠错相关的论文中,字符之间的编辑操作基于Damerau-Levenshtein distance,有以下4种:
a.增加一个字母
b.删除一个字母
c.用一个字母替换另一个字母
d.交换相邻的字母
在这篇论文中,作者提出了更一般的error model,允许从字符 α到字符β的所有编辑操作。除了上面的这4种情况,另外还考虑了字符编辑操作发生的位置信息,包括单词的开始、单词的中间、单词的末尾。位置信息是一个很重要的特征,比如人们很少将antler错写为entler,却经常将reluctant写成reluctent。
模型表述:
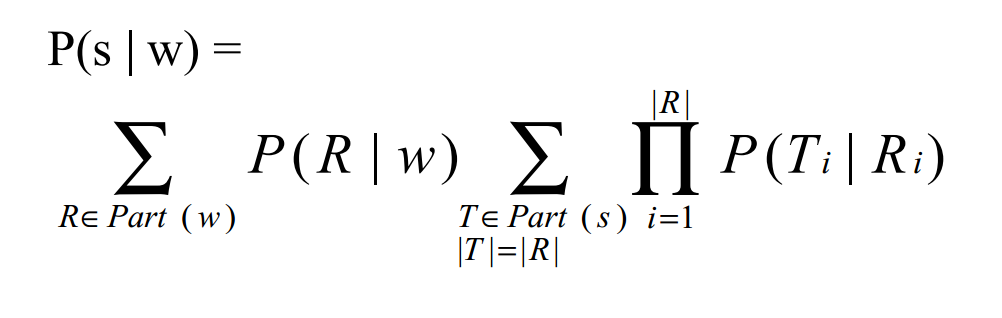
其中,w为用户期望输入字符,s为实际输出字符。Part(w)表示将字符w划分为相邻子串的各种形式集合,R属于Part(w)中的一个特殊的划分,由j个连续片段组成。
3.论文模型训练
训练模型需要纠错对,即{\(w_{i},s_{i}\)}这样的纠错对。首先对纠错对按照单词级别进行对齐,比如纠错对:{akgsual,actual},做如下方式的对齐:
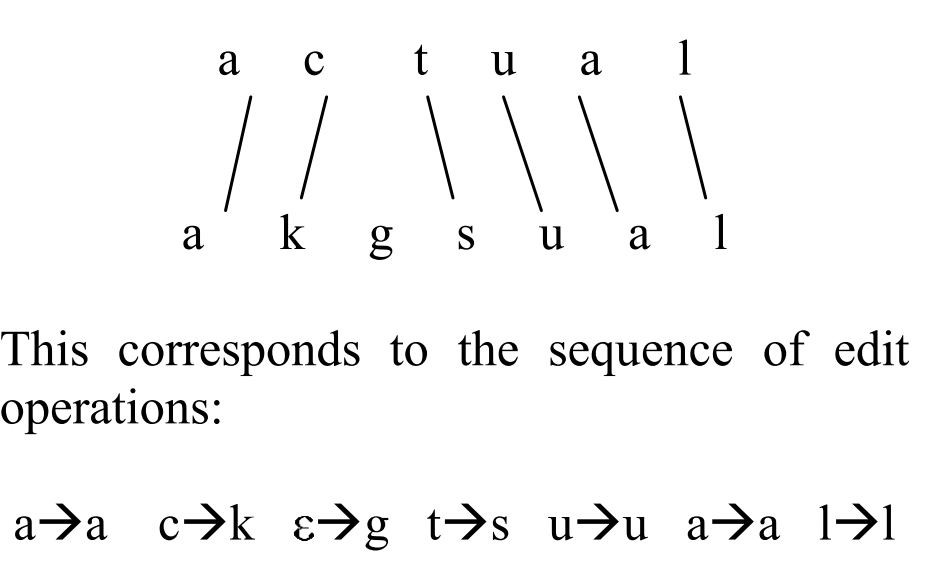
为了丰富上下文特征,对未对齐的字符进行N个相邻的扩展,如下所示:
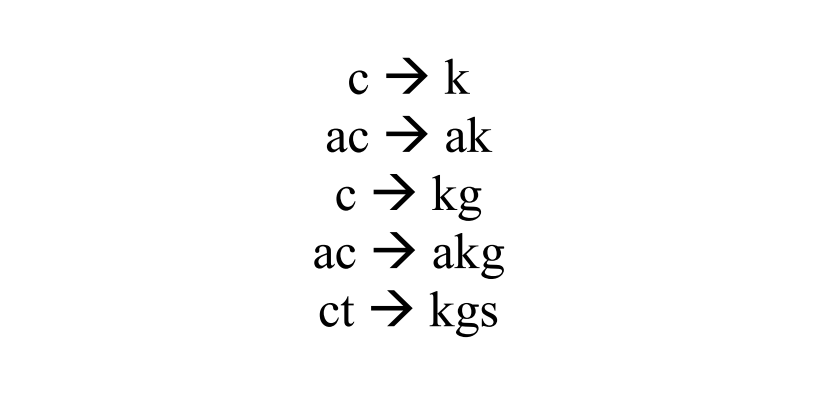
然后统计数量,计算子串α到子串β的转移概率。
4.模型应用
输入字符w,而实际输出的是s,s是可见的而w是不可见的。给定输出结果s,期望返回最有可能的w。即\(argmax_{w} P(w | s)P(w | context) \)。
首先将词典预编译成trie树,其中每个trie节点是一个权重数组,存储的是字符s和当前节点字符前缀之间的编辑距离。另外存储从 α->β的参数概率,将参数集合中所有子串α出现在替换对α->β左边的字符存放于trie树中,每个节点是α,指向出现在替换对α->β右边的β的trie树,在β trie树末节点存放子串概率。
将α和β逆序存放,然后可以通过整个词典来高效的计算编辑距离。从词典trie树根节点开始遍历,找到可用的替换对参数,给出在trie树中的节点和在输入单词s中的位置,在α树中从根节点开始查找,如果找到尾结点,根据指针找到对应的β树。
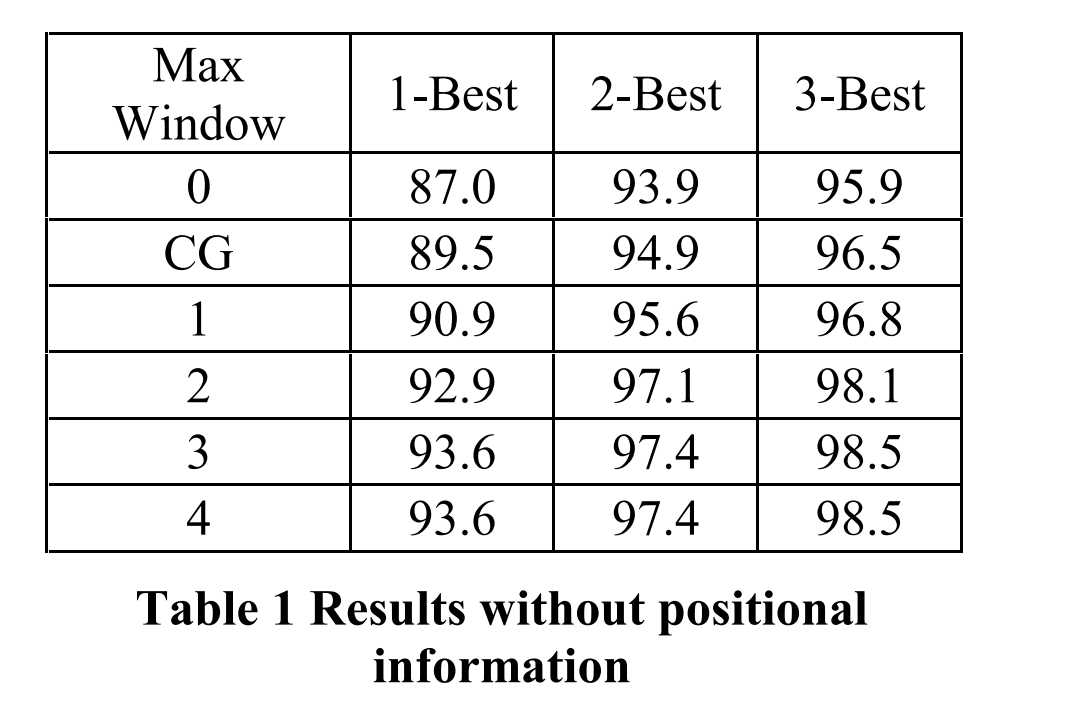
5.结果