Youdao’s Winning Solution to the NLPCC-2018 Task 2 Challenge: A Neural Machine Translation Approach to Chinese Grammatical Error Correction
这篇论文是有道团队在2018 NLPCC会议语法纠错任务中的分享,他们取得了第一的成绩。具体如下:
1.中文语法纠错
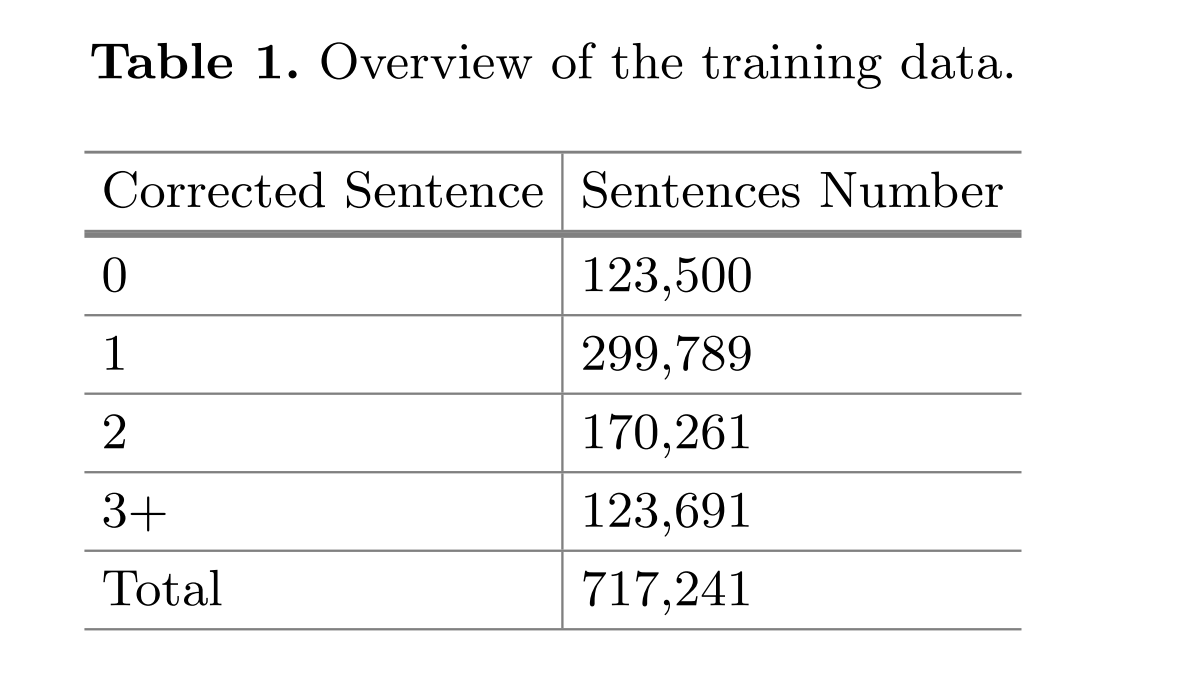
目标是检测并纠正中文语句中的语法错误,有多种方法能够处理语法错误修正问题,包括纯粹基于规则的方法、基于多种错误类型的分类器组合方法以及基于机器翻译方法等。这个属于NLPCC 2018的新增任务。会议提供的训练数据是由中文初学者写的,并且由本土中文人士改进。每个句子可能有0~N个纠正结果,句子分布情况如下:
训练数据样例如下:

2.具体方案
论文中作者将中文语法纠错任务转换为翻译问题,让神经网络学习错误句子和正确句子之间的关联,并且将错误句子翻译为正确的句子。作者采用了3阶段的处理方法:预处理阶段目标是移除浅层错误,包括拼写和标点等错误;转换阶段来识别和修正语法错误;组合阶段将前面两个阶段进行组合产生最终的输出结果。
2.1数据预处理
在这个任务中除了NLPCC提供的训练数据,另外还使用了两个公共数据集:
a.语言模型:
语言模型用来评测一个词语序列成为一个句子的概率,特别是一个语法正确的句子语言模型得分要高于一个不正确或者不常见的句子。作者使用的语言模型是基于2500万中文句子训练的5-gram语言模型。
b.相似字符集
中文中好多错误是由于相似的字形或者相似的发音造成的,所以作者从SIGHAN 2013 CSC 数据集中构建了相似字形和相似发音的集合。如下所示:

作者在这里使用相似字符集来产生候选;语言模型来选择最合适的一个候选。
NLPCC数据集预处理
训练机器翻译模型需要预料对(srcSent,tgtSent),其中srcSent表示原始句子即可能存在错误的句子,tgtSent表示目标句子。NLPCC 2018提供的训练集每个句子对应一个或者多个正确句子,原始数据集包含了71万语句对,作者处理后得到了122万语句对。如果srcSent中不存在错误,则设置tgtSent与srcSent相同;如果srcSent存在多个错误,则进行分拆形成多个语句对。然后用5-gram语言模型进行过滤,最终得到76万语句对。
2.2拼写错误纠正
这一部分主要是采用拼写错误模型来去除大多数浅层错误。采用5-gram的语言模型,长度为n的词语序列w的概率得分为:
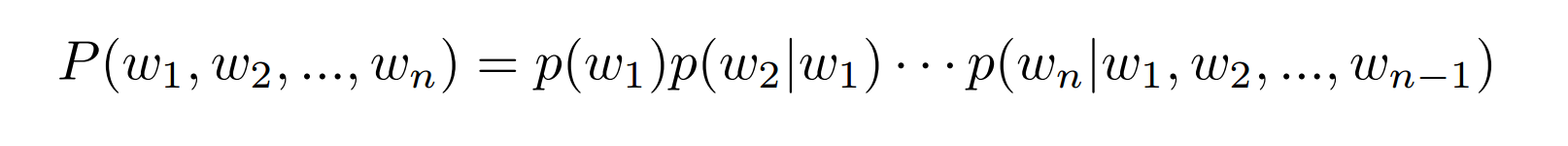
困惑度的计算公式:
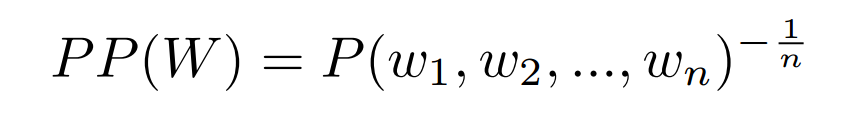
这里使用困惑度作为语言模型的得分,困惑度越高,成为句子的可能性越低。
具体操作来说,首先将句子x以字为粒度进行切分,对于句子中的每个字c,看是否在SCS集合中出现,若出现则生成c的替代集合;然后用替代集合中的每个字去替换c;最后通过语言模型选择困惑度最低的一个句子。
2.3 语法错误纠正模型
在移除拼写错误后,将语法错误视为翻译问题,并采用了NMT(神经网络翻译)模型。NMT基于encoder-decoder,encoder将输入句子\((x_{1},x_{2},…x_{n})\)编码成隐层序列\((h_{1},h_{2},…h_{n})\),decoder根据隐层序列产生最终的输出序列\((y_{1},y_{2},…y_{m})\)。在这里作者选择的是Tranformer,Transformer中的Attention机制如下:
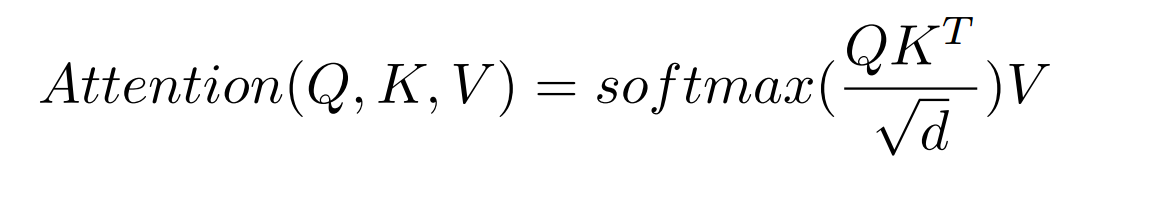
作者使用的是基于tensorflow的开源实现:tensor2tensor去训练模型,隐层参数是800,其他参数默认。
2.4 模型组合和重排序
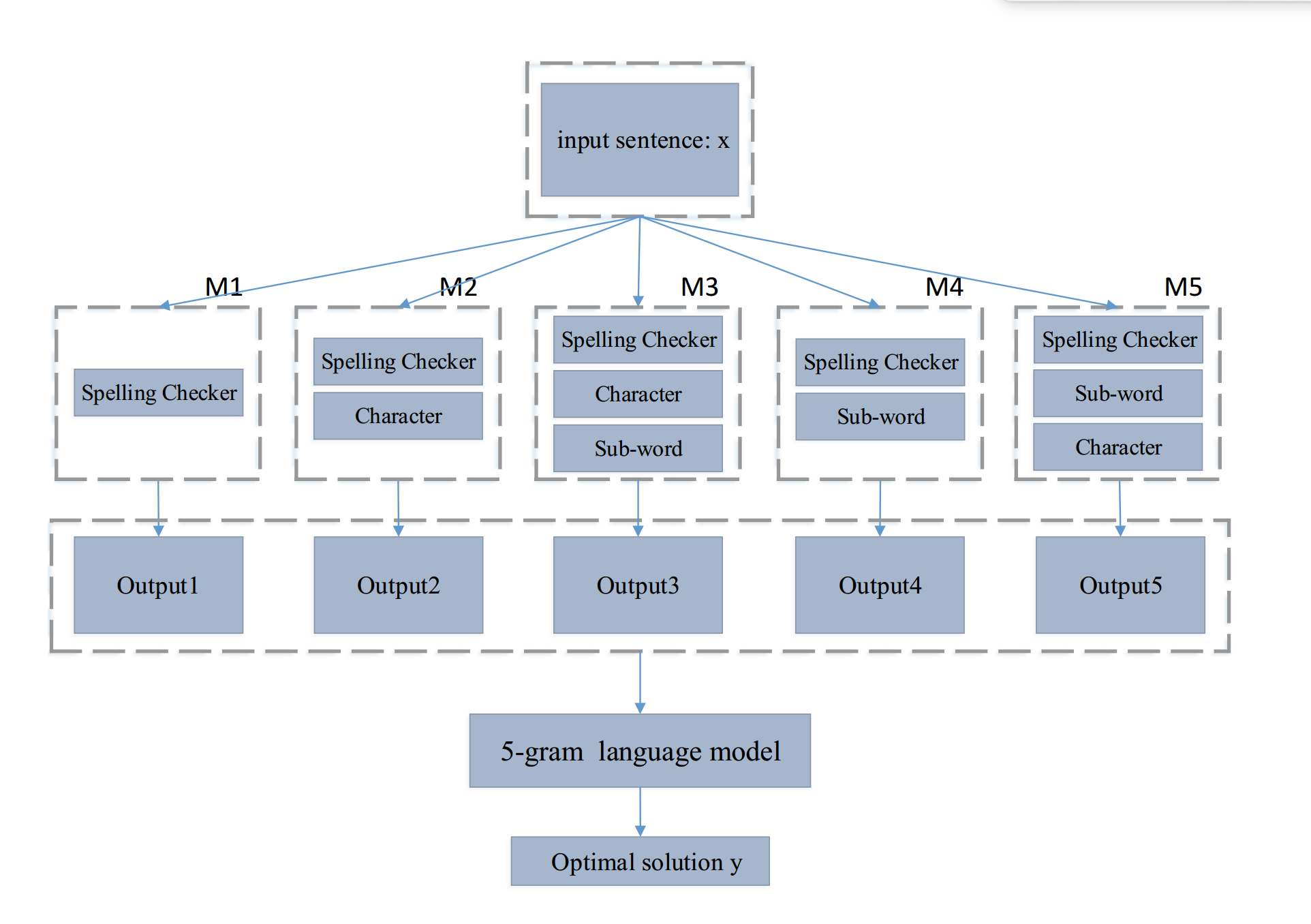
NMT模型可以有不同的配置方式,比如基于字的和基于词的设置。为了处理少见和OOV的问题,基于子词的方式经常使用。在神经网络翻译中,基于子词的方式效果最好,但是在中文纠错中存在不同的错误,每个错误可能会用到不同的配置。所以这里使用了模型组合,然后采用了一个重排序机制来选择不同模型中最好的结果。
具体来说,5个模型的配置如下:
M1:单纯的拼写纠错
M2:拼写纠错+基于字的NMT
M3:拼写纠错+基于字+基于子词的NMT
M4:拼写纠错+基于子词的NMT
M5:拼写纠错+基于子词+基于字的NMT
M3和M5使用了相同的模型,但是顺序不一致。整个处理过程如下:
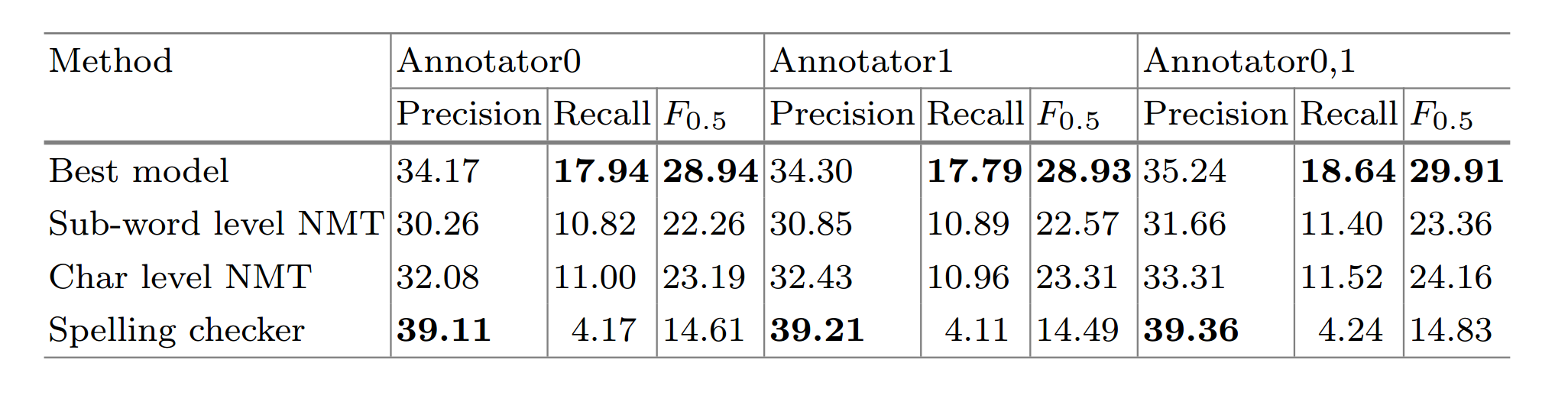
3.实验结果
在76万纠错对中,选择3000组作为验证集,剩下的作为训练集。结果如下